Appearance
注意力机制
你有没有想过:
- ❓为什么AI能读懂“我今天吃的苹果,红色的,很甜,不是苹果手机”这句话里,两个“苹果”指的是完全不同的东西?
- ❓为什么AI在翻译长句子时,不会像我们背课文一样“前背后忘”,能准确地保持上下文的连贯?
- ❓为什么GPT模型可以处理那么长的文本,而过去的AI却像“金鱼”一样只有7秒记忆?
所有这些问题的答案,都指向了同一个革命性的概念——🌟注意力机制 (Attention Mechanism)🌟。这不仅是一个技术,更是AI认知能力的一次“寒武纪大爆发”。
1. 注意力之前的方案
在Transformer诞生之前,处理文本序列(比如一句话)的主流型是循环神经网络(RNN),以及它的变种LSTM
想象一下RNN是怎么读一句话的:“今天 天气 真 不错” 它会一个词一个词地读:
- 1.读了“今天”,形成一个记忆。
- 2.读了“天气”,把“天气”的信息和“今天”的记忆打包成一个新的记忆
- 3.读了“真”,把“真”的信息和“今天天气”的记忆再打包成一个更新的记忆。
- …以此类推。 这个过程就像一个不断滚动的雪球,试图把整句话的信息都压缩进最后一个“记忆雪球“里。
这种模式有什么致命缺陷?
- “金鱼”般的短期记忆(Short-term Memory):当句子非常长时信息在一次次的“打包“过程中会不断丢失和稀释。读到第50个词的时候,它可能早就忘了第一个词是什么了。这就是所谓的“长距离依赖问题”。
- 无法并行计算,效率低下:它必须一个词一个词地按顺序处理,就像一根糖葫芦,你必须先吃完第一个才能吃第二个。这在需要处理海量数据的今天,速度慢得令人发指。
- 信息瓶颈(Information Bottleneck):它强迫模型把一整句话的“万千气象”都硬塞进一个固定大小的“记忆雪球”(上下文向量)里,这本身就是不合理的。
这就好比让你蒙着眼睛,只通过触摸来读一篇长文,每摸一个字,就要把之前所有字的感觉都记在脑子里,读到最后,你还能记得开头写了啥吗?
2. 注意力的诞生-像人一样去阅读!
人类是怎么阅读的?我们并不会给每个字分配相同的“关注度”
当读到句子:“The animal didn't cross the street because it wastoo tired.”(那个动物没有过马路,因为它太累了。)
我们的大脑在理解“it”(它)这个词时,会 自动、快速地将注意力集中到前面的“animal”(动物)上,而不是“street”(街道)。我们知道“它“指的是"动物”,而不是“马路”。
这个有选择性地关注重点信息的能力,就是注意力的核心思想!
科学家们深受启发:“我们能不能让AI也学会这种能力?
划重点:
注意力机制(Attention Mechanism)允许模型在处理一个序列时,能够像人类一样,动态地、有选择性地关注输入序列中最重要的部分,而不是对所有信息一视同仁。它打破了必须将所有信息压缩成一个固定向量的“魔咒”。
它赋予了模型一双“慧眼”,让它在处理每个词时,都能回头“看一看“整个句子,并判断:“哪些词跟我关系最密切?我应该重点关注谁?
3. 注意力的核心-Q、K、V
注意力的“魔法”核心--Q、K、V三剑客
好了,进入本篇最硬核、也最关键的部分:注意力到底是怎么计算的?别怕,我们不用一行代码,只用一个生活中的比喻,就能把它彻底搞懂!
3.1 想象一下你在图书馆查资料的过程
你要写一篇关于“人工智能”的论文,你脑子里有个具体的问题,比如“大模型的最新进展”。这个具体的问题,就是你的查询(Query,简称Q)
图书馆里有无数本书,每本书都有一个书名标签(Key,简称K),比如“机器学习简史”、“深度学习原理”、“大模型应用实践”等等。
每本书里面,都有丰富的内容(Value, 简称V)。
你的查资料过程是这样的:
第一步:匹配度打分
你拿着你的问题Q(大模型的最新进展),去和每一本书的书名标签K做对比。
- Q vs.K(“机器学习简史”)→ 匹配度可能只有 30分。。
- Q vs.K(“深度学习原理”)→ 匹配度可能有 60分。
- Q vs.K(“大模型应用实践”)→ 匹配度高达 95分!
第二步:分配注意力权重
根据这些分数,来分配你的“注意力精力”。你会把90%的精力放在那本95分的书上,剩下的精力随便分给其他书。这个“精力分配比例”,就是注意力权重(Attention Weights)。所有书的权重加起来等于100%(或1)。
第三步:加权求和,获取信息
你根据分配好的权重,去吸收每本书的内容V。
- 最终你获得的信息 =90%《大模型应用实践》的内容+6%。《深度学习原理》的内容 + …
最后,你得到的,是一个高度相关、融合了所有书籍精华、并且重点突出的知识集合。
3.2 现在,我们把这个过程搬到AI身上
一句话就是一座“图书馆”,每个词既可以作为“查询者”,也拥有自己的“标签“和“内容”。
以句子“AI 改变 世界“为例,当模型处理“改变”这个词时:
- “改变”这个词自己,会生成一个
Q(Query)向量,- 句子里的每一个词(包括“改变”自己),都会生成一个
K(Key)向量和一个V(Value)向量。K可以理解为这个词的,,V是这个词的
计算开始:
- 计算注意力分数: 拿出“改变“的Q,分别去和“AI“的K、“改变”的K、“世界”的K进行数学运算(通常是点积),得到三个注意力分数。这个分数代表了“改变”这个词,应该对其他词有多“关注”。(比如“改变“和“AI”、“世界”的关系肯定比和它自己的关系更紧密)
- 归一化(Softmax): 用一个叫Softmax的函数,把这些分数转换成
注意力权重,确保它们的总和=1。比如,结果可能是:“AI“权重0.4,“改变”权重0.2,“世界“权重0.4。
- 归一化(Softmax): 用一个叫Softmax的函数,把这些分数转换成
- 加权求和: 用这些权重,去乘以每个词对应的V向量,然后把它们全部加起来。
- 最终结果 = 0.4 * V(“AI”) + 0.2 * V(“改变”) + 0.4 * V(“世界”)
这个最终结果,就是“改变”这个词在理解了整句话上下文之后的全新表示!它不再是孤零零的“改变”,而是融合了“AI“和“世界“信息的、更有深度、更丰富的“改变”。
这个过程会对句子中的每一个词都进行一遍。最终,整句话的每个词都“焕然一新”,充满了对全局上下文的理解。
4. 自注意力与Transformer
上面讲的这个过程,有一个更酷的名字--自注意力机制(Self-Attention)。
自“体现在哪里?体现在Q、K、V都来源于同一个输入序列。是句子在“自己看自己”,内部的词在互相“关注”,从而理解内部的语法和语义结构。
而2017年那篇惊世骇俗的论文《Attention Is Al You Need》正是基于这个“自注意力“机制,构建了一个全新的模型架构一Transformer。
Transformer的强大是什么?
- 彻底抛弃RNN的序列依赖: 在自注意力中,任何两个词之间的“关注度“计算,都只取决于它们本身,与其他词无关。这意味着,对所有词的注意力计算,都可以同时进行!这带来了巨大的并行计算能力,训练速度相比RNN发生了质的飞跃,使得训练干亿、万亿参数的大模型成为可能。
- 多头注意力(Multi-Head Attention): 这是另一个天才设计。模型不会只用一套Q,K,V去“看”句子。而是像昆虫的复眼一样,同时拥有
多套(比如8套、12套)独立的Q,K,V,我们称之为“头”。- 比喻:这就像让一群专家同时阅读一句话
- 语法专家头可能会关注主谓宾结构。
- 语义专家头可能会关注词语之间的指代关系(比如“it”和animal")。
- 时态专家头可能会关注动词和时间状语的联系。
- 每个“头”都能从不同的角度捕捉句子中的信息,最后再把所有头“的观察结果整合起来,形成一个无比丰富和立体的理解。
- 比喻:这就像让一群专家同时阅读一句话
- 位置编码(Positional Encoding): 自注意力虽然强大,但它天生“不知顺序”(因为所有词都是同时计算的)。为了让模型知道词语的先后顺序,“我爱你”和“你爱我”是不同的,Transformer在末端端给每个词叠加上一个包含其位置信息的"数学标签”,这就是
位置编码。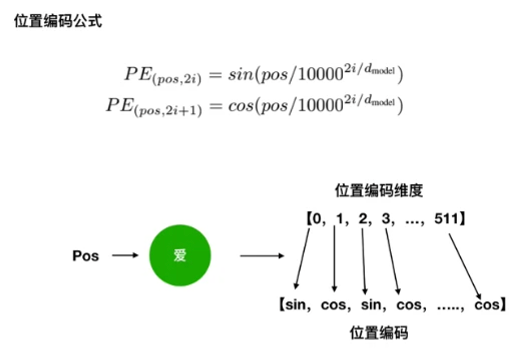
基石
自注意力 + 多头注意力 + 位置编码,这三者共同构成了Transformer模型的核心骨架,也是今天所有GPT系列、LLaMA系列等大模型屹立不倒的基石。
5. 注意力的深远影响与未来
注意力机制的出现,不仅仅是模型性能的提升,更是AI发展范式的深刻变革。
- 从“序列压缩“到“全局关联”:它彻底摆脱了RNN/LSTM那种试图将无限信息压缩进有限记忆的困境,转向了一种更高效、更灵活的“全局动态关联“模式。
- 可解释性的窗口:虽然大模型整体上是“黑箱”,但我们可以通过可视化注意力权重,来“窥探“模型在做决策时,到底在“看“什么。这为我们理解和调试模型提供了一个宝贵的窗口。
- 跨模态的统一:注意力的思想是普适的。它不仅能处理文本,同样能处理图像(把图像切成小块,让小块之间互相“注意”),处理声音实现了文本、图像、声音等不同模态数据在同一个模型架构下的统一。
当然,它也有挑战,比如自注意力计算量与序列长度的平方成正比,导致处理超长文本时成本极高。这也是为什么现在有各种“稀疏注意力”、“线性注意力“等改进方案在不断涌现。
6. 总结
- 注意力机制的核心:模仿人类阅读习惯,让AI有选择性地关注输入信息中的重要部分。
- 工作原理(Q,K,V):通过Query(查询)、Key(标签)Value(内容),模型可以计算出每个词对于其他词的“关注度”,并基于此生成融合了全局上下文的全新词表示
- 自注意力(Self-Attention):是注意力的关键应用,让句子“自己理解自己”,是Transformer架构的基石。
- 革命性影响:带来了强大的并行计算能力和对长距离依赖的出色捕捉,使得训练超大规模模型成为可能,开启了AIGC的黄金时代。