Appearance
Softmax回归分类过程
例如有3个类别,分别是 A、B、C
分类预测函数:
- 其中 是权重矩阵, 是输入特征向量, 是偏置项向量。
- 输出 是一个向量,每个元素对应一个类别的预测值。
1. 对样本进行编码
对训练样本,按类别进行一位有效编码 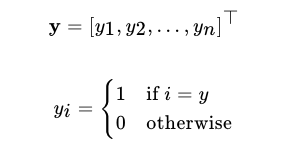
一个样本,按标签数据进行编码, 对应每个类别的真实在概率分别
- 如果是 A 类,那么编码为 [1, 0, 0]
- 如果是 B 类,那么编码为 [0, 1, 0]
- 如果是 C 类,那么编码为 [0, 0, 1]
2. 获取每个类别预测概率
例如有一个样本,模型输出为 [0.2, 0.7, 0.1]
- 对应 A 类的概率为 0.2
- 对应 B 类的概率为 0.7
- 对应 C 类的概率为 0.1
取最大值,那最有可能的是 B 类
这种方法虽然简单,但不够精细。
3. 余量约束
我们希望正确类别的预测值,要明显高于错误类别的预测值。形成一个明显的差距,或者说余量。 增加预测结果的置信度。
比如要求:
- 其中 是正确类别的预测值, 是错误类别的预测值,Delta 是一个超参数,用来控制余量的大小。
4. Softmax 函数
但是仅有余量约束, 并不能直接得到概率分布。
概率特点:
- 0-1之间的,非负数
- 所有概率之和为 1
我们需要通过 Softmax 函数,将预测值转换为概率分布。
这里,。 因此,可以视为一个正确的概率分布。
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。 因此,softmax回归是一个线性模型(linear model)。
这样一来,模型的输出就变成了类似概率的形式,比如 [0.2, 0.7, 0.1] 就表示模型预测为 A 类的概率为 0.2,B 类的概率为 0.7,C 类的概率为 0.1。
5. 交叉熵损失
交叉熵损失用来衡量模型预测的概率分布与真实标签的差异。
差的越多,损失就越大, 模型就越需要调整。
交叉熵从到,记为。 我们可以把交叉熵想象为“主观概率为的观察者在看到根据概率生成的数据时的预期惊异”。 当时,交叉熵达到最低。 在这种情况下,从到的交叉熵是。
简而言之,我们可以从两方面来考虑交叉熵分类目标:
- (i)最大化观测数据的似然;
- (ii)最小化传达标签所需的惊异。