Appearance
线性回归简单实现
在过去的几年里,出于对深度学习强烈的兴趣, 许多公司、学者和业余爱好者开发了各种成熟的开源框架。 这些框架可以自动化基于梯度的学习算法中重复性的工作。
1. 生成数据集
python
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
# 权重
true_w = torch.tensor([2, -3.4])
# 偏置项
true_b = 4.2
'''
生成y=Xw+b+噪声
features中的每一行都包含一个二维数据样本,
labels中的每一行都包含一维标签值(一个标量)。
'''
features, labels = d2l.synthetic_data(true_w, true_b, 1000)通过生成第二个特征features[:, 1]和labels的散点图, 可以直观观察到两者之间的线性关系。 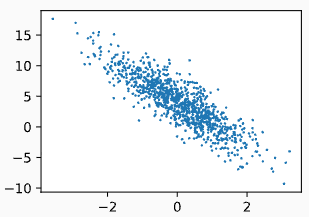
2. 读取数据集
可以调用框架中现有的API来读取数据。 我们将features和labels作为API的参数传递, 并通过数据迭代器指定batch_size(小批量训练集)。 布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据。
python
def load_array(data_arrays, batch_size, is_train=True): #@save
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)生成第一个小批量数据样本并打印
python
next(iter(data_iter))
'''
打印结果:
[tensor([[-1.3116, -0.3062],
[-1.5653, 0.4830],
[-0.8893, -0.9466],
[-1.2417, 1.6891],
[-0.7148, 0.1376],
[-0.2162, -0.6122],
[ 2.4048, -0.3211],
[-0.1516, 0.4997],
[ 1.5298, -0.2291],
[ 1.3895, 1.2602]]),
tensor([[ 2.6073],
[-0.5787],
[ 5.6339],
[-4.0211],
[ 2.3117],
[ 5.8492],
[10.0926],
[ 2.1932],
[ 8.0441],
[ 2.6943]])]
'''3. 定义模型
因为我们要学习一个线性模型,所以我们需要一个只有一个输出的线性层。 该层将每个输入特征作为输入,每个输出特征作为输出。 注意,第一个参数指定输入特征的数量,第二个参数指定输出特征的数量。
python
# nn是神经网络的缩写
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))4. 初始化模型参数
在使用net之前,我们需要初始化模型参数。
如在线性回归模型中的权重和偏置。 深度学习框架通常有预定义的方法来初始化参数。
这里我们指定每个权重参数应该从均值为0、标准差为0.01的正态分布中随机采样, 偏置参数将初始化为零。
python
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)5. 定义损失函数
我们使用均方误差损失函数。 它在PyTorch的nn模块中称为MSELoss类,也称为平方L2范数。
默认情况下,它返回所有样本损失的平均值。
python
loss = nn.MSELoss()6. 定义优化算法
小批量随机梯度下降算法是一种优化神经网络的标准工具, PyTorch在optim模块中实现了该算法的许多变种。
当我们实例化一个SGD(优化算法)实例时, 我们要指定优化的参数(可通过net.parameters()从我们的模型中获得)以及优化算法所需的超参数字典。
小批量随机梯度下降只需要设置lr值,这里设置为0.03。
python
trainer = torch.optim.SGD(net.parameters(), lr=0.03)7. 训练
在每次迭代中,我们将完整遍历一次数据集(data_iter), 不停地从中获取一个小批量的输入和相应的标签。 对于每一个小批量,我们会进行以下步骤:
- 计算预测值和损失(通过调用net(X)和loss(y_hat, y)分别计算)(前向传播)
- 通过反向传播计算梯度(调用trainer.step())
- 将参数更新(调用trainer.step())
我们将重复此过程num_epochs次。 每次完成对数据集的迭代后,我们计算一次模型在训练集上的损失, 并打印它来监控训练过程。
python
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')打印结果:
epoch 1, loss 0.000248
epoch 2, loss 0.000103
epoch 3, loss 0.000103