Appearance
循环神经网络RNN
RNN(Recurrent Neural Network),循环神经网络。
你是否曾好奇:
- ❓为什么你的手机输入法,在你输入"生日"后,会立刻提示"快乐"?
- ❓为什么机器翻译软件,能读完一整句"今天天气真不错",再翻译成"It's a nice day today",而不是逐字翻译成"Today weather really not bad"?
- ❓为什么Siri能听懂你一长串的指令,而不是只对最后一个词有反应?
这些看似理所当然的智能背后,都隐藏着一个共同的秘密,那就是让机器拥有短期记忆的能力。而RNN,就是实现这种记忆魔法的开山鼻祖。
传统的神经网络,就像一个记忆只有七秒的金鱼,你给它看一张猫的图片,它能认出是猫;但你紧接着再给它看一张狗的图片,它已经完全忘记了刚才看到过猫。它的每一次判断都是孤立的、瞬时的。
然而,我们人类理解世界的方式并非如此。我们看电影、读小说、听音乐,都依赖于对上下文(Context)的记忆。前一秒的剧情,会影响我们对下一秒的期待;上一句话的内容,决定了我们如何理解下一句话。
AI要想真正理解我们的语言、我们的世界,就必须摆脱金鱼脑,进化出能够处理序列信息(Sequential Data)的人类脑。
1.金鱼脑vs阅读者
想象一下,我们有两种方式来阅读一本书。
1.金鱼脑阅读法(对应:前馈神经网络/FNN)
你是一个记忆只有几秒钟的金鱼。你每次只能看到书中的一个词。
- 当你看到"我"这个词,你只知道这是个"我"字。
- 下一秒,书页翻动,你看到"爱"这个词。此时你已经完全忘了上一个词是什么你只知道这是个"爱"字。
- 再下一秒,你看到"你"。你同样只知道这是个"你"字。
对于金鱼来说,它看到了三个独立的汉字:"我"、"爱"、"你”。它永远无法理解这三个字连在一起表达了"Ilove you"这个完整的含义。
这就是前馈神经网络(FNN,Feed-Forward Neural Network),比如我们常说的普通分类网络,所面临的困境。它们处理信息是单向、无记忆的。每一个输入都是一次全新的开始,与之前的输入毫无关联。这对于处理图片分类等独立任务来说足够了,但对于理解语言、预测股价等序列任务则完全无能为力。
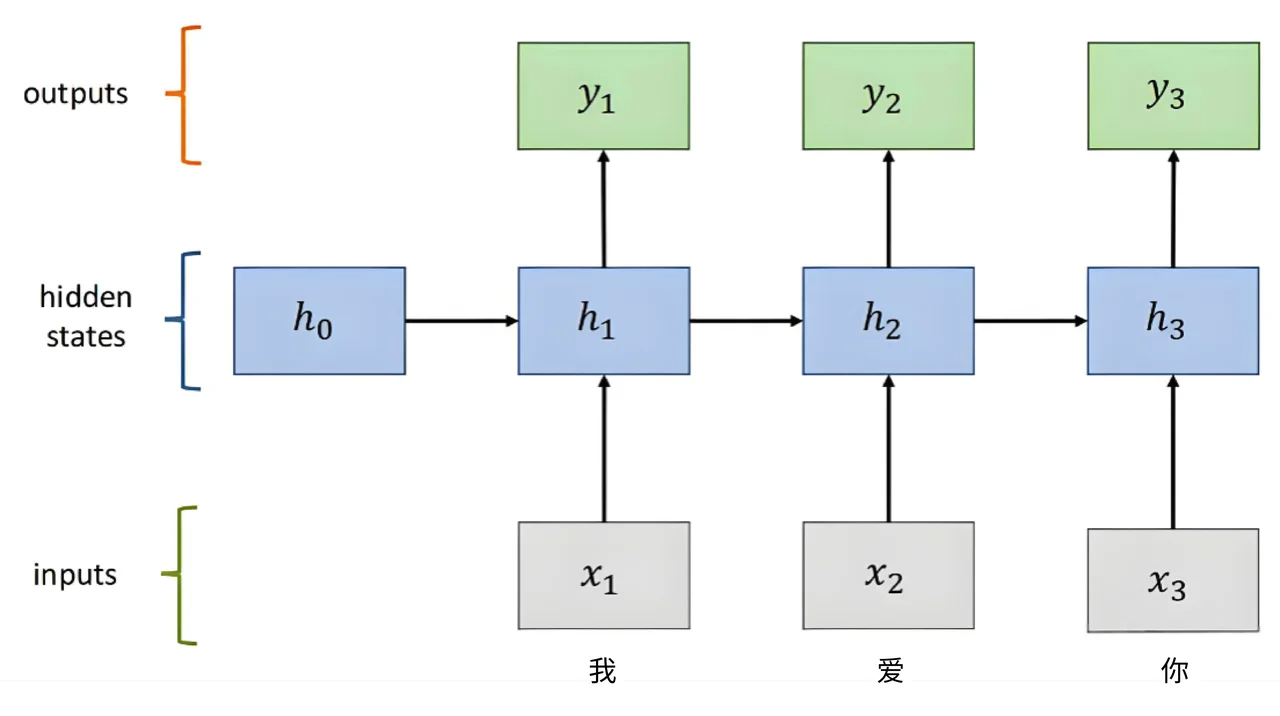
2.阅读者阅读法(对应:循环神经网络/RNN)
现在,你是一个正常的人类阅读者。你不仅能看到当前的词,你的大脑里还保留着来自前面所有内容的短期记忆。
- 当你看到第一个词"我"时,你把它记在脑子里。
- 当你看到第二个词"爱"时,你的大脑会自动将它与之前的"我"联系起来,形成一个初步的印象:"我爱…"。这个印象,就是你的
记忆状态。- 当你看到第三个词"你"时,你的大脑再次更新,将"你"与"我爱…"这个记忆状态结合,最终理解了整句话的含义。
这个过程,就是循环神经网络(RNN)的核心思想。RNN设计了一种巧妙的结构让网络在处理序列中的每一个元素时,都能回顾之前的信息。
RNN的魔法核心,就在于它引入了一个循环的结构,每一次的输出,不仅取决于当前的输入,还取决于上一次的记忆状态。这个记忆状态就像一个滚动的雪球,随着序列的推进,不断把新的信息包裹进来,形成对整个序列越来越全面的理解。
2.RNN的记忆循环是如何工作的?
理解了宏观的比喻,现在让我们戴上工程师的眼镜,看看这个神奇的记忆循环在技术上是如何实现的。 别怕公式,我们会用最直白的方式解释。
想象一个RNN的基本单元,我们叫它RNN细胞(RNNCel)。这个细胞是整个网络的核心,它会被重复使用来处理序列中的每一个元素
在一个时间步(Time step)t,这个细胞会做三件事:
1.接收两个输入
- 当前的输入
x(t):比如,当前看到的这个词"爱"。 - 上一个时间步的记忆
h(t-1): 这是细胞在处理上一个词"我"时,形成的记忆摘要。h代表隐藏状态(Hidden state),是RNN记忆的载体,也是整个RNN的精髓所在。
2.进行内部计算,更新记忆
- 细胞内部有一套固定的计算规则(由权重矩阵
w和u定义),它会把当前的输入x(t)和旧的记忆h(t-1)搅拌在一起。 - 这个搅拌过程,通常是通过一个
激活函数(比如tanh)来完成的,公式大概长这样:h(t) = tanh( w * h(t-1) + u * x(t))
- 划重点: 新的记忆
h(t),是由旧记忆和当前输入共同决定的。这就实现了信息的传递和累积。
3.产生两个输出
- 当前时间步的输出
y(t): 基于最新的记忆h(t),网络可以做出一个预测。比如,在我爱后面,预测下一个最可能的词是什么。 - 新的记忆
h(t): 这个新鲜出炉的记忆,将作为输入,传递给下一个时间步的同一个RNN细胞,去处理序列中的下一个元素。
看到这个流程了吗? h(t) 既是当前时间步计算的结果,又是下一个时间步计算的输入。这就形成了一个跨越时间的循环(Recurrence)。网络仿佛在对自己说:这是我刚处理完爱之后的记忆总结,现在我把它交给未来的我,让未来的我去处理你这个词。
一个至关重要的概念:权重共享(Weight Sharing)
在处理一个序列(比如一句话)时,从第一个词到最后一个词,RNN使用的都是一套计算规则,也就是同一组权重矩阵w和U。这非常符合直觉,就像我们人类用同一套语法理解能力去解析一句话里的所有词语,而不是每个词都换一种新的理解方式。
权重共享带来了两大好处:
- 极大减少了模型的参数量: 无论序列有多长,模型的参数都是固定的
- 让模型学到通用的规律: 模型学会的是一种处理序列的通用方法,可以泛化到不同长度的序列上
3.RNN弱点-长期依赖问题
基础RNN的设计号称天才,但它很快就暴露出了一个致命的弱点:它是个金鱼脑的升级版,但记性依然很差,尤其擅长选择性遗忘。这就是著名的长期依赖问题(Long-Term Dependency Problem)
想象这个句子:
"我出生在法国,……(中间省略一万字描述童年生活),因此我能说一口流利的___?
为了填上最后的词法语,模型必须把记忆回溯到最开始的法国。如果中间隔了太多的信息,基础RNN的记忆会变得非常模糊,它很可能已经忘记了"法国"这个关键信
这个问题在技术上源于RNN的训练方式,具体表现为两个噩梦:
1.梯度消失(Gradient Vanishing)
这是最常见的问题。在训练网络时,我们需要根据最终的预测错误,来反向调整每一个时间步的权重。这个修正信号,我们称之为梯度(Gradient)。
在RNN中,这个梯度需要从序列的末尾,一步步地传回序列的开头(反向传播)。就像一个传话游戏:
- 最后一个人(预测"法语”的地方)发现预测错了,他把这个"错误信息"告诉前-个人。
- 前一个人再告诉他前面的人,以此类推。
由于在每一步传递时,这个梯度信号都会乘以一个小于1的因子(激活函数的导数),经过很多步之后,这个信号会指数级衰减。传到最开始处理"法国"的那个细胞时信号已经微弱到几乎为零。
结果就是:模型无法从遥远的过去中学习。仿佛在说:"好吧,我最后预测错了,但这个错误好像跟最开始的那个词没什么关系,我就不调整那部分的权重"于是, 长期依赖关系就学不到了
2.梯度爆炸(Gradient Exploding)
这是梯度消失的反面。如果在传递过程中,梯度信号总是乘以一个大于1的因那么传到开头时,这个信号就会变得无比巨大,像雪崩一样。
结果就是:训练过程极其不稳定。 模型的权重会发生剧烈的、无意义的更新就像一个学生因为一道题没做对,就把整本书都撕了。整个学习过程直接崩溃
虽然梯度爆炸可以通过一些技术手段(如梯度裁剪)来缓解,但更为棘手的梯度消失,则直接催生了RNN家族的伟大进化,
4.RNN的进化-LSTM与GRU
为了解决基础RNN的健忘症,两位超级英雄闪亮登场:长短期记忆网络(LSTM,Long Short-Term Memory)和门控循环单元(GRU,Gated RecurrentUnit)
它们的核心思想非常一致:与其让信息无差别地、被动地在时间中传递和衰减不如给RNN细胞装上阀门(Gate),让它主动地、有选择地去管理记忆
1.LSTM:拥有精细化笔记系统的大脑
LSTM是RNN进化史上的一座丰碑。它把原本简单的RNN细胞,改造成极其精密的大脑笔记系统。这个系统有两条记忆线和三个控制门。
两条记忆线:
- 细胞状态(Cell State, Ct):这是LSTM的主记忆线,像一条平稳的传送带。信息在这条线上流动非常顺畅,可以轻松地穿越很长的时间序列而不失真。这就是
解决长期依赖的关键!它代表长期记忆。 - 隐藏状态(Hidden State, ht):这和RNN里的一样,更多地
代表基于长期记忆和当前输入,形成的短期记忆或当前工作记忆,用于指导当前的输出。
三个精密的控制门(Gate):
a.遗忘门(Forget Gate):
- 作用:
决定应该从长期记忆(细胞状态)中丢弃哪些信息- 比喻: 你的大脑笔记的
橡皮擦。- 例子:当你读到一个新的主语时,比如"小明…",然后句子变成了"小红…",遗忘门就会起作用,把关于小明的性别、年龄等信息从记忆中擦除一部分,为新主语小红的信息腾出空间。
b.输入门(Input Gate):
- 作用:
决定哪些新信息应该被加入长期记忆(细胞状态)。- 比喻: 你的大脑笔记的
荧光笔。它先用荧光笔划出当前输入中的重点,再决定用多大的力气(强度)把这些重点写进笔记本。- 例子:看到"小红"之后,紧接着看到了"穿着一条漂亮的裙子"。输入门会判断,"裙子"这个信息对于理解"小红"的形象很重要,于是决定将这个新信息写入细胞状态。
c.输出门(Output Gate):
- 作用:
决定应该从长期记忆(细胞状态)中提取哪些信息,用于当前的输出。(短期记忆ht)- 比喻: 你的大脑笔记的
发言人。它会审视整个笔记本的内容,然后决定在当前这个时间点,说出哪句最相关的话。- 例子:句子是"小红穿着漂亮的裙子,她看起来很开心,下一个词要预测她做什么"。输出门会查看细胞状态里的"开心"这个记忆,然后决定输出一个与"开心"相关的动作,比如"笑了"。
通过这三个门的协同工作,LSTM获得了对记忆的精细化、动态化的控制能力。让它知道什么时候该遗忘,什么时候该记忆,什么时候该输出,从而完美地解决了长期依赖问题。 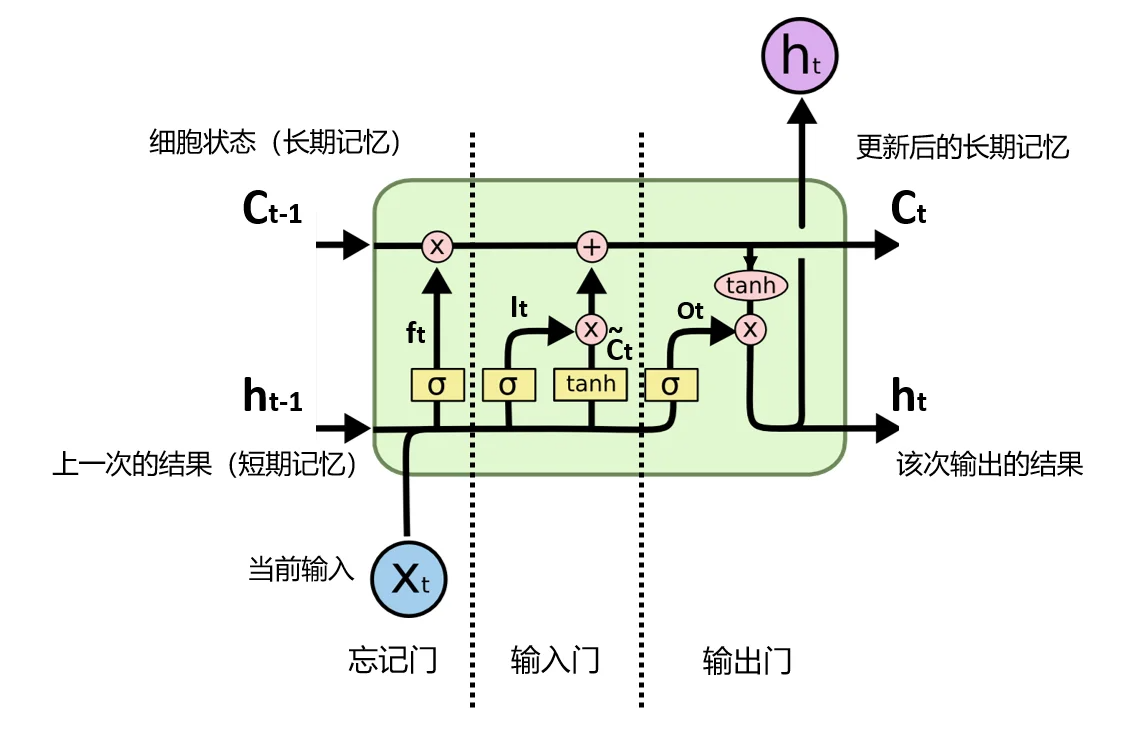
2.GRU: LSTM的轻量化高效版
GRU是LSTM的一个非常流行且更年轻的变体。可以把它看作是LSTM的轻装版,它的目标是在保持LSTM强大功能的同时,简化结构,提高计算效率。
GRU做了一些聪明的简化:
- 合并记忆线: 它没有独立的细胞状态(长期记忆),而是将所有记忆都放在了隐藏状态 ht 中。
- 简化控制门: 它只有两个门:
- 更新门(Update Gate):巧妙地将LSTM的遗忘门和输入门的功能合二为一,它同时决定要忘掉多少旧信息,以及要加入多少新信息。
- 重置门(Reset Gate):决定在多大程度上忽略掉过去的记忆,来计算新的候选记忆。
对比:GRU就像一个更务实的笔记系统,虽然不如LSTM那么精细,但在很多任务上,它的效果和LSTM旗鼓相当,而计算速度却更快。因此,在实际应用中,当计算资源有限或追求更高效率时,GRU是一个非常棒的选择.
5.RNN现状
讲到这里,很多关注AI前沿的宝子可能会问:现在不是都说Transformer和注意力机制才是王道吗?BERT、GPT这些大模型不都是基于Transformer的吗?我们花这么大力气学习RNN、LSTM,还有用吗?
这是一个非常好的问题。答案是:绝对有用,而且理解RNN是理解更复杂模型的基础。
1. Transformer的崛起
自2017年Transformer模型横空出世后,它凭借其强大的并行计算能力和卓越的全局信息捕捉能力(自注意力机制),在自然语言处理(NLP)领域取得了统治性的地位。
- RNN/LSTM的瓶颈:
它们是天生串行的。必须先处理完第一个词,才能处理第二个词,这限制了它们在超大规模数据和GPU集群上的训练效率。- Transformer的优势:
可以并行处理一句话中的所有词。它就像把整页书摊开一眼就能看到所有词,并通过注意力机制直接计算出任意两个词之间的关联度无论它们相距多远。这对于捕捉长距离依赖关系,比LSTM的记忆传送带更加直接和强大。
2. RNN的价值犹在
尽管风头被抢,但RNN及其变体在今天的AI世界里,依然扮演着不可或缺的角色,并且是学习AI绕不开的基石。
- 理论基石: RNN是第一个成功处理序列数据的模型范式。理解了RNN的循环结构和门控机制,你才能更好地理解Transformer中
位置编码的必要性,以及为什么序列建模如此重要。它是通往更高阶模型的必经之路。- 特定领域的优势: 在很多不需要超长距离依赖、或者数据本身具有强烈时序性的场景中,RNN/LSTM/GRU依然是高效且强大的工具。例如:
- 时间序列预测: 预测股票价格、预测天气变化、预测用户行为等。这些任务。中,近期的信息往往比遥远的信息更重要,非常适合RNN的建模方式
- 边缘计算与移动端: 由于模型结构相对简单、参数量较少,LSTM和GRU非常适合部署在手机、智能手表、物联网设备等计算资源受限的环境中。
- 混合模型: 在很多先进的模型中,RNN依然作为组件被使用。比如在一些图像描述生成模型(Image Captioning)中,会
用CNN提取图像特征,再用LSTM来生成描述性的句子。
6. 总结
- 问题的起源: 传统神经网络是金鱼脑,无法处理有
前后关联的序列数据(如语言、时间序列)。这使得它们在处理如文本、语音、视频等序列数据时,表现得非常有限。 - RNN的核心思想: 引入
记忆循环,让网络在处理当前输入时,能够参考上一个时间点的隐藏状态(记忆)。通过权重共享,用一套规则处理整个序列。 - RNN的硬伤: 存在长期依赖问题,表现为
梯度消失(记不住)和梯度爆炸(记忆错乱),导致难以学习长序列中的规律。 - RNN进化--LSTM & GRU:
- LSTM: 引入
细胞状态(长期记忆)和遗忘门、输入门、输出门这三个控制阀门,实现了对记忆的精细化管理,完美解决了长期依赖问题。 - GRU: LSTM的轻量化变体,结构更简单,计算更高效,效果依然强大。
- LSTM: 引入
- 当下的地位: 虽然在很多大型NLP任务上,风头被更善于并行计算的Transformer盖过,但RNN家族依然是理解序列建模的理论基石,并在时间序列预测、边缘计算等领域发挥着不可替代的作用。