Appearance
基础概念
人工智能中的一些基础概念,后续会详细介绍。
1. 拟合
拟合Fitting 是统计学和机器学习中的一个重要概念,指的是模型对数据的适应能力。具体来说,拟合就是通过调整模型的参数,使得模型能够尽可能地接近或匹配观测到的数据。
1.1 拟合的类型:
正确拟合:模型能够很好地适应训练数据,并且在验证数据上也有较好的表现。这意味着模型既没有过拟合也没有欠拟合。过拟合:模型在训练数据上表现非常好,但在新的、未见过的数据上表现很差。这是因为模型过度关注了训练数据中的噪声和细节,而没有学习到数据的真正模式或规律。欠拟合:模型在训练数据上的表现就不够好,通常是因为模型过于简单,无法捕捉到数据中的复杂模式。
1.2 如何避免过拟合和欠拟合
增加数据量:更多的训练数据可以帮助模型学习到更广泛的数据特征,减少过拟合的风险。减少模型复杂度:通过降低模型的复杂度,如减少神经网络的层数或决策树的深度,可以避免过拟合。正则化:在损失函数中加入正则项,如L1和L2正则化,可以惩罚模型参数的大小,防止模型过于复杂。早停法:在模型训练过程中,监控模型在验证集上的性能,当性能不再提升时停止训练,防止过拟合。
2. 损失函数
损失函数(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。
回归问题中最常用的损失函数是平方误差函数,当样本的预测值为,其相应的真实标签为时, 平方误差可以定义为以下公式:
常数不会带来本质的差别,但这样在形式上稍微简单一些 (因为当我们对损失函数求导后常数系数为1)。
3. 梯度下降
梯度下降(gradient descent)是一种优化算法,用于最小化损失函数(预测值尽量接近真实值)。 这种方法几乎可以优化所有深度学习模型。 它通过不断地在损失函数递减的方向上更新参数来降低误差。
Scholarly科普了一个很好的解释:

想象一个盲人登山者想要从山顶下到山谷的最低点。他看不到整个地形,只能通过脚下的坡度来判断方向。这个盲人会用脚试探周围的地面,感受哪个方向的坡度最陡峭(梯度),然后朝着这个方向迈出一小步。每一步的大小(学习率)取决于他对地形的”信心”--如果坡度很陡,他可能会迈小步以防摔倒;如果坡度平缓,他可能会迈大步加快速度。
在梯度下降中,目标函数就像这座山的地形当前位置就是盲人所在的位置,梯度就是盲人感受到的坡度方向,而学习率就是盲人决定每一步迈多大的”谨慎程度”。通过反复试探和移动,盲人最终能够找到山谷的最低点。这个比喻生动地说明了梯度下降的核心思想: 通过局部信息(梯度)来指导全局优化方向,通过迭代的方式逐步逼近最优解。
3.1 学习率的重要性
学习率 ŋ是梯度下降中最关键的参数之一:
- 学习率过小: 收敛速度很慢,需要很多次迭代才能到达最小值点。这就像盲人每一步都迈得特别小,虽然安全但效率低下。
- 学习率过大: 可能导致算法发散,无法收敛。这就像盲人步伐太大,直接”跨过”了山谷甚至可能越走越高。
- 最优学习率选择: 实践中通常通过实验来确定合适的学习率。

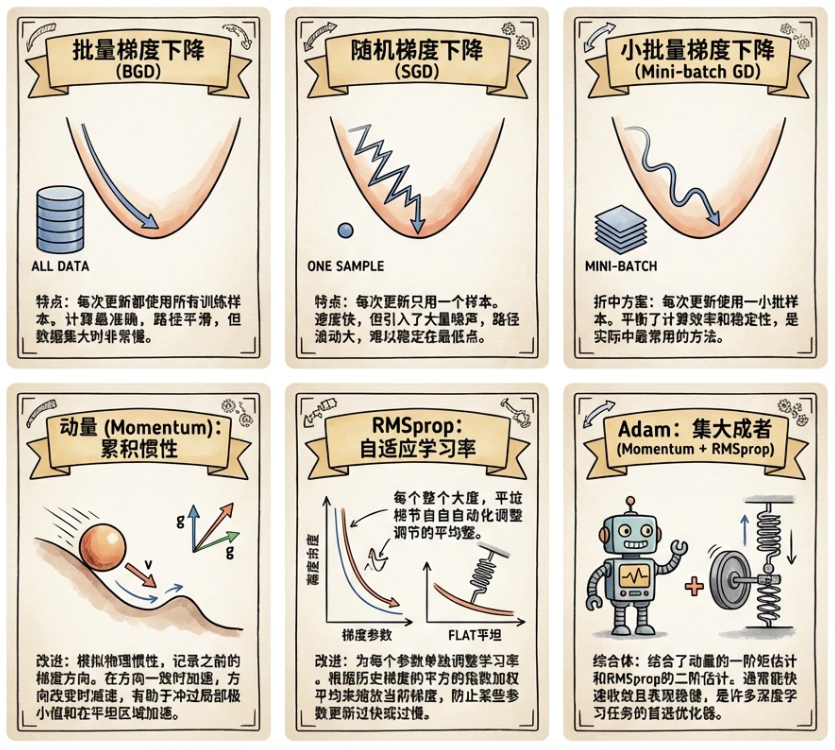
3.2 小批量随机梯度下降
使用整个数据集进行梯度下降会比较慢。因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。
在每次迭代中,我们首先随机抽样一个小批量, 它是由固定数量的训练样本组成的。 然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。 最后,我们将梯度乘以一个预先确定的正数,并从当前参数的值中减掉。
我们用下面的数学公式来表示这一更新过程(表示偏导数):
总结一下,算法的步骤如下:
- (1)初始化模型参数的值,如随机初始化;
- (2)从数据集中随机抽取小批量样本且在负梯度的方向上更新参数,并不断迭代这一步骤。
3.3 梯度下降变体