Appearance
暂退法(Dropout)
在深度学习和机器学习模型训练中,我们常常面临 过拟合(Overfitting) 的问题。
为了提高模型在未见数据上的泛化能力,正则化(Regularization) 技术应运而生。
其中,最常用的一种正则化方法就是——暂退法(又叫丢弃法 Dropout),核心思想是在模型训练过程中随机地丢弃(即设置为0)网络中的一部分神经元,从而降低神经元之间的复杂共适应关系,提高模型的泛化能力。
Dropout的神经网络图像:
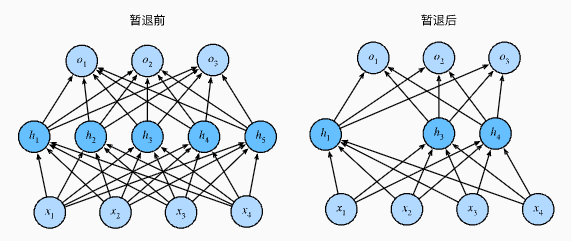
典型的Dropout概率
这种设定源自大量经验总结,能够在防止过拟合的同时,保证训练过程的有效性。
输入层(Input Layer) :
- 通常会以 20% 的概率将输入层神经元随机置零(丢弃)。
- 输入特征通常经过工程处理或是人类设计,已经是比较精炼的,因此如果丢弃过多,容易导致信息丢失,因此Dropout概率设置较低(20%)。
隐藏层(Hidden Layer) :
- 通常会以 50% 的概率将隐藏层神经元随机置零(丢弃)。
- 隐藏层的神经元通常数量很多且存在冗余,适当提高Dropout概率(50%),可以有效破除神经元间复杂的相互依赖,提高网络的泛化能力。
Dropout在训练和推理阶段的差异
- 训练阶段 Dropout随机屏蔽神经元,抑制复杂的共适应现象。
- 推理阶段(测试/预测阶段) Dropout不再屏蔽任何神经元,而是将训练阶段的输出统一缩放(scale),以保证期望值的一致性。
在TensorFlow早期版本中,需要手动设置keep_prob; 而在PyTorch、TensorFlow 2中,框架内部会自动处理训练和推理时的差异,无需手动干预。
实现
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层, 将暂退概率作为唯一的参数传递给它的构造函数。 在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)
python
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);总结
- 合理选择Dropout位置: Dropout并不是越多越好,一般只在隐藏层或者输入层使用,不建议在输出层使用
- 根据模型复杂度调整Dropout率: 对于大型复杂模型,可以适当增加Dropout概率;对于小型模型,Dropout率应适度降低,以免导致欠拟合。
- 暂退法仅在训练期间使用。
- 与其他正则化方法结合: Dropout可以与L2正则化(权重衰减)、Batch Normalization等技术搭配使用,提高效果。