Appearance
梯度消失和梯度爆炸
什么是梯度
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
- 梯度是一个向量,即有方向有大小;
- 梯度的方向是最大 方向导数 的方向;
- 梯度的值是最大 方向导数 的值
梯度下降法
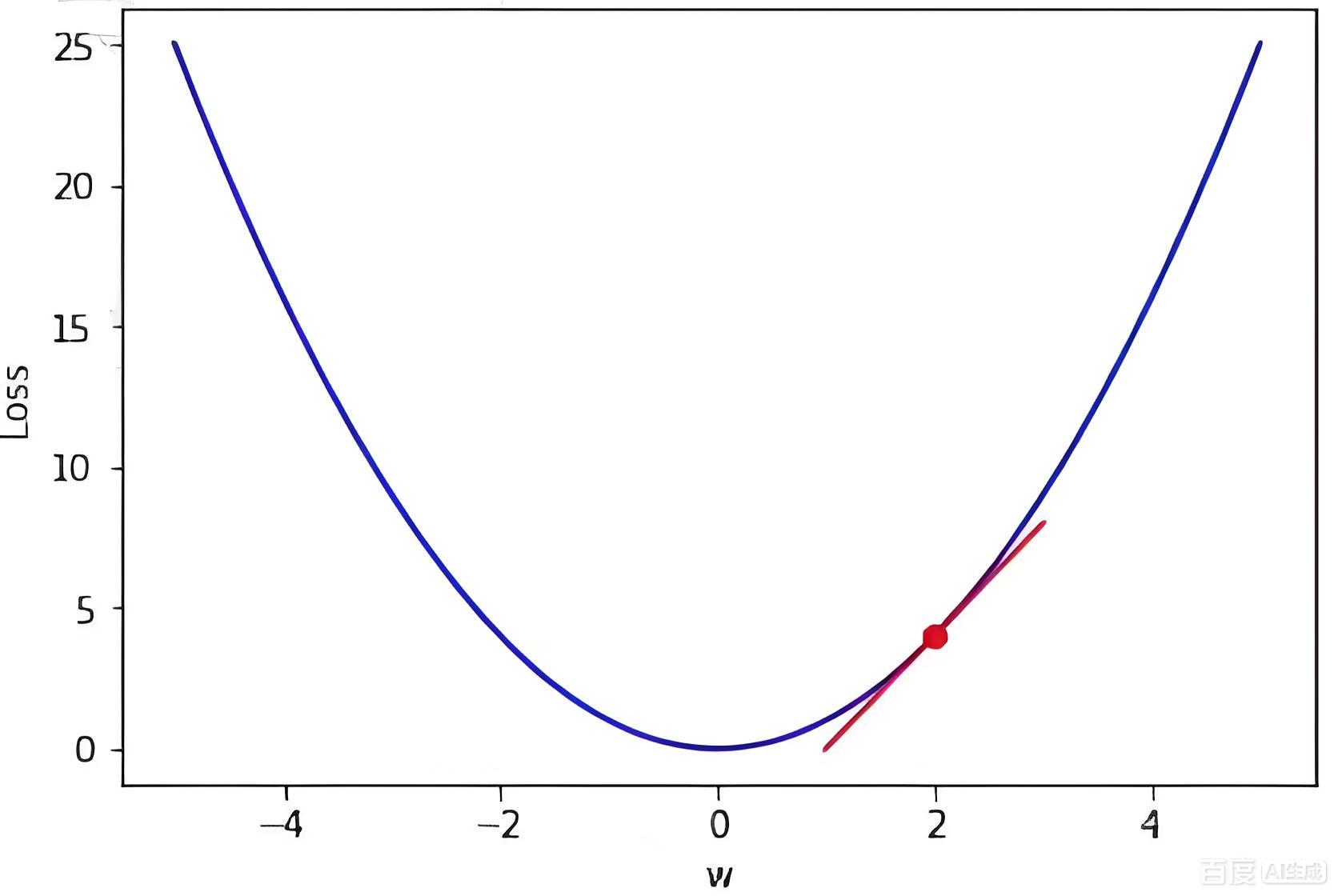
梯度下降(gradient descent)是一种优化算法,用于最小化损失函数(预测值尽量接近真实值)。 这种方法几乎可以优化所有深度学习模型。 它通过不断地在损失函数递减的方向上更新参数来降低误差。
在梯度下降中,目标函数就像这座山的地形当前位置就是盲人所在的位置,梯度就是盲人感受到的坡度方向,而学习率就是盲人决定每一步迈多大的”谨慎程度”。通过反复试探和移动,盲人最终能够找到山谷的最低点。这个比喻生动地说明了梯度下降的核心思想: 通过局部信息(梯度)来指导全局优化方向,通过迭代的方式逐步逼近最优解。
梯度消失
在梯度下降法中, 随着算法反向的反馈, 梯度会越来越小,最终归零没有变化,但此时并没有收敛到比较好的解,这就是梯度消失的问题。
就是山太平,导致下山路长
激活函数sigmoid, 会导致梯度消失问题。
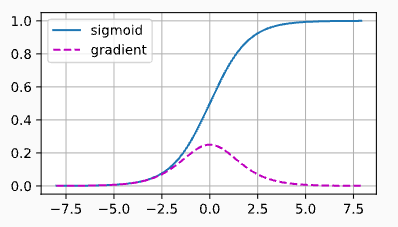
正如上图,当sigmoid函数的输入很大或是很小时,它的梯度都会消失。 此外,当反向传播通过许多层时,除非我们在刚刚好的地方, 这些地方sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。 事实上,这个问题曾经困扰着深度网络的训练。 因此,更稳定的ReLU系列函数已经成为从业者的默认选择(虽然在神经科学的角度看起来不太合理)。
梯度爆炸
梯度爆炸是深度神经网络训练中,反向传播的梯度值指数级增大导致数值溢出(如NaN)的问题,会使参数更新失控、模型无法收敛
就是山太高,导致下山路长
为什么会出现梯度爆炸?
梯度爆炸的核心是反向传播时梯度值被逐层放大,常见原因包括:
- 激活函数特性:ReLU等函数在正区间导数为1,若权重初始化过大,梯度会累积放大。
- 权重初始化不当:初始值过大(如全设成10),前向传播激活值爆炸,反向传播梯度随之失控。
- 学习率过高:放大梯度更新幅度,导致参数剧烈震荡。
- 深层网络累积效应:每层导数>1时,梯度按链式法则指数增长(例如10层网络梯度可能放大1000倍)。