Appearance
模型选择
深度学习目标:
在给定有限数据量的情况下寻找合适的模型(模型选择)
训练模型的目标是发现泛化模式(pattern), 这些模式捕捉到了我们训练集潜在总体的规律。 如果成功做到了这点,即使是对以前从未遇到过的个体, 模型也可以成功地评估风险。 如何发现可以泛化的模式是机器学习的根本问题。
过拟合 就是泛化能力差。
1. 训练误差和泛化误差
模型选择的目标是找到一个模型, 它在训练数据上的误差最小, 同时在测试数据上的误差也最小。
训练误差(training error)是指, 模型在训练数据集上计算得到的误差。泛化误差(generalization error)是指, 全新的数据上的期望误差。- 永远不能准确地计算出泛化误差
2. 影响模型泛化的因素
2.1. 样本差异导致泛化差
独立同分布假设(i.i.d. assumption)
假设训练数据和测试数据都是从相同的分布中独立提取的。 这通常被称为独立同分布假设(i.i.d. assumption), 这意味着对数据进行采样的过程没有进行“记忆”。 换句话说,抽取的第2个样本和第3个样本的相关性, 并不比抽取的第2个样本和第200万个样本的相关性更强。
现实数据违反独立同分布假设的情况是非常常见的。
- 时间依赖
- 地域差异
- 场景差异
2.2.模型复杂度对泛化差的影响
模型的复杂性要和数据的复杂性匹配。过于复杂的模型会记住训练数据中的噪声, 影响泛化能力
- 模型复杂度对欠拟合和过拟合的影响
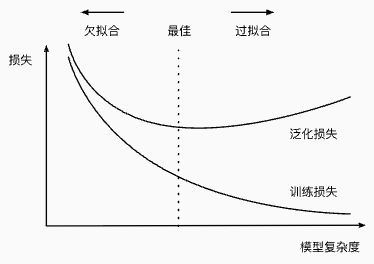
2.3. 数据集大小
训练数据集中的样本越少,我们就越有可能(且更严重地)过拟合。 随着训练数据量的增加,泛化误差通常会减小。
2.4.其它影响模型泛化的因素
- 可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
3. 模型选择
在机器学习中,我们通常在评估几个候选模型后选择最终的模型。 这个过程叫做模型选择.
- 有时,需要进行比较的模型在本质上是完全不同的(比如,决策树与线性模型)
- 有时,我们需要比较不同的超参数设置下的同一类模型。
为了确定候选模型中的最佳模型,我们通常会使用验证集。
3.1. 数据三分法
将数据集分为三部分:训练集、验证集和测试集。
训练集用于训练模型验证集用于选择模型测试集用于评估模型的泛化能力
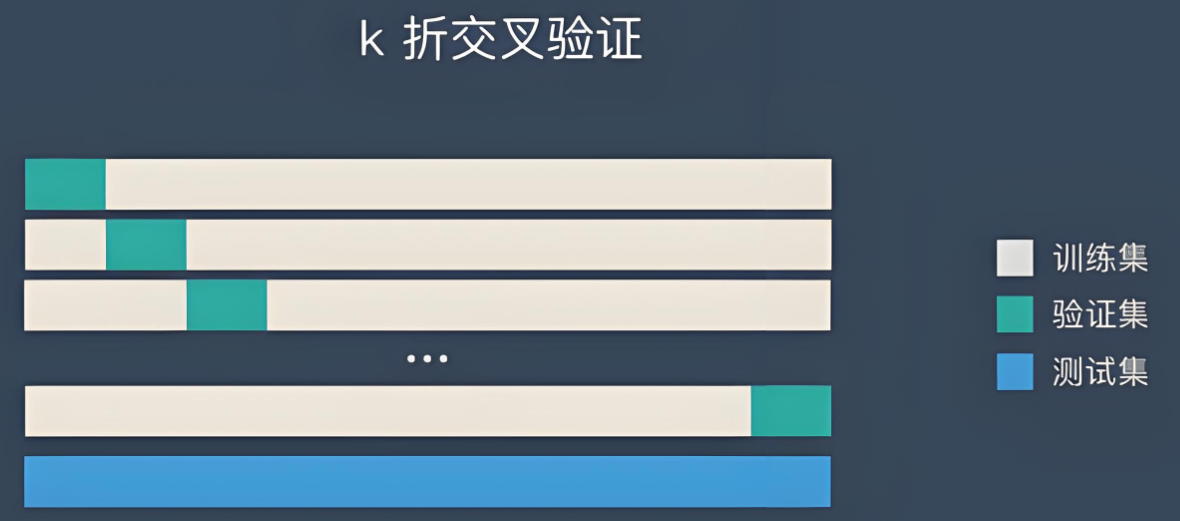
3.2. K折交叉验证
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。 这个问题的一个流行的解决方案是采用 折交叉验证。 这里,原始训练数据被分成 个不重叠的子集。 然后执行 次模型训练和验证,每次在 个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。 最后,通过对 次实验的结果取平均来估计训练和验证误差。
4. 正则化-解决"学过头"
训练集表现很好,测试集拉胯 → 过拟合。正则化就是给网络加约束。
4.1. 常见手段:
| 方法 | 思路 | 一句话 |
|---|---|---|
| L1正则 | 损失函数加权重绝对值 | 稀疏化,特征选择 |
| L2正则 | 损失函数加权重平方 | 权重衰减,防过大 |
| Dropout 暂退法 | 随机丢神经元 | 别太依赖某条路 |
| Batch Norm 批量归一化法 | 归一化每层输出 | 稳训练、有正则化副作用 |
| Early Stopping 早停 | 验证集不再提升就停 | 别练了,够了 |
| Data Augmentation 数据增强法 | 数据增强 | 见多识广不偏科 |
4.2. 正则化对比激活函数
| 激活函数 | 正则化 | |
|---|---|---|
| 解决什么 | 表达能力 | 泛化能力 |
| 核心问题 | 网络能不能学到复杂模式 | 网络会不会学过头 |
| 一句话 | 让网络能学 | 让网络别学死 |
没有激活函数,不管堆多少层,输出都是输入的线性组合。
它们的交集
虽然维度不同,但有些地方边界模糊:
- Dropout —— 既是网络结构操作,又是正则化手段
- Batch Norm —— 本意是稳定训练,但自带轻微正则化效果(因为每个batch的均值方差有噪声)
- ReLU的稀疏激活 —— ReLU让约一半神经元输出0,这种稀疏性本身就有隐式正则化效果
- 权重衰减 + ReLU —— L2正则配合ReLU,会把不重要神经元的权重推向0,配合稀疏性效果更强