Appearance
卷积神经网络 CNN
在聊CNN之前,我们先来做一个简单的小互动
- 请看一眼你身边的任何一个物体,比如一个水杯。
- 现在,我把它稍微挪动一下位置,再让你看。你依然认得它
- 我把它旋转一个角度,你还认得它。
- 我把它拿到光线更暗的地方,你依然认得它
- 我甚至用手挡住它的一半,你的大脑也能立刻脑补出它完整的样子
对我们人类来说,这一切都发生得如此自然,以至于我们从未思考过,这个识别的过程,到底有多么神奇和复杂。
但在计算机的眼中,世界完全是另一番模样。一张图片,对它来说,只是一个由几百万个代表着颜色和亮度的数字(像素)组成的、巨大而冰冷的矩阵。
- 你把图片里的水杯向右平移了10个像素,对于计算机来说,整个数字矩阵都变了!它看到的是一张全新的、完全不同的图片
- 你把图片的光线调暗了一点,矩阵里所有的数字也都变了!
那么,AI是如何克服这种死板的数字视角,学会像我们人类一样,从千变万化的像素中,识别出物体本质的呢?
这个问题的答案,就是人工智能中的一个重要概念卷积神经网络(CNN)!
1.传统神经网络的视觉障碍
要理解CNN的革命性,我们必须先看看传统全连接神经网络(Fully Connected Neural Network,FCNN), 用FCNN来做图像识别,会遇到两个灾难问题!
参数爆炸--多到无法承受
问题:FCNN的全连接特性,意味着上一层的每一个神经元,都要和下一层的每一个神经元相连接。- 计算一下:假设我们有一张小小的 100x100 像素的彩色图片。
- 这张图片的输入层,就需要100x100x3(RGB三通道)=30,000 个神经元。
- 如果我们的第一个隐藏层,也设置了30,000个神经元。
- 仅仅是从输入层到第一个隐藏层,所需要的连接数(也就是权重参数),就是 30,000x30,000=9亿!
后果:要训练这么多的参数,不仅需要无法想象的计算资源,模型也会因为参数过多而极易陷入过拟合(死记硬背训练图片,无法泛化到新图片)。而这还只是一张小图片的网络的第一层而已!
空间结构丢失--把世界揉成一团
问题:FCNN在处理图片时,会先把100x100的二维像素矩阵,粗暴地拉伸成一个30,000 维的一维长向量。后果:这个拉伸的动作,彻底破坏了图像中至关重要的空间结构信息
- 在原始图片中,像素A和像素B是相邻的,它们共同构成了一条边缘,而在拉伸后的向量中,像素A和像素B则是完全独立的。
- 这意味着,FCNN无法理解上下左右这样的空间概念。它就像一个把一幅完整的拼图打散成一堆单个碎片,然后试图去理解这幅画内容的脸盲症患者
2.灵感来源
CNN的横空出世,其灵感来源于对生物视觉系统的模仿,特别是我们大脑的视觉皮层。
上世纪50-60年代,两位神经科学家Hubel和Wiesel的诺贝尔奖级研究发现:
- 我们大脑的视觉皮层中,存在一些初级视觉神经元。这些神经元,并不会对整个视野做出反应,而是只对自己负责的一小块区域(感受野)内的、特定方向的边缘或线条,产生强烈的激活。
- 更高级的神经元,则会将这些初级神经元的信号组合起来,以识别更复杂的形状,比如角点、曲线
- 这个过程层层递进,最终,在最高级的视觉中枢,我们形成了对一张脸、一只猫等复杂物体的认知。
- 这个过程,类似做拼图,初级神经元识别较小的分块,更高层的神经元识别拼接后的大分块,逐步递归,组成整张图片。
CNN的架构设计,完美地复刻了生物视觉的这两个核心洞察:
生物视觉核心洞察:
- 局部感受野(Local Receptive Fields): 神经元不需要看整张图,只需要关注一小块局部区域。
- 层次化特征提取(Hierarchical Feature Extraction): 从简单的边缘,到局部的形状,再到整体的物体,认知是层层抽象的。
基于这两个洞察,CNN引入了它最核心、最神奇的三大法宝:卷积(Convolution)、激活(Activation)和池化(Pooling)
下面,我们来详细了解一下这三大法宝是如何协同工作的。
3.卷积层-特征提取大师
卷积层(Convolutional Layer) 是CNN的灵魂所在!它的目标,就是从原始的像素矩阵中,提取出各种有用的局部特征。
核心工具:卷积核(Kernel)/滤波器(Filter)
- 它是什么: 你可以把它想象成一个个小小的、带有特殊任务的放大镜或特征探测器。
- 它的样子: 它本质上是一个小的矩阵,它的大小通常是
3x3、5x5。矩阵里的数字(权重),决定了这个探测器的任务是什么,
- 例如:一个专门探测垂直边缘的卷积核,可能长这样:[[1, 0, -1], [1, 0, 1], [1, 0, -1]]
- 例如:一个专门探测水平边缘的卷积核,可能长这样:[[1, 1, 1], [0, 0, 0], [-1, -1, -1]]
- 还有的卷积核,在训练后,可能会自发地学会去探测特定的颜色、角点、或者某种纹理。
重要
这些卷积核里的权重,不是人为设计的,而是和神经网络的权重一样,是通过反向传播,从数据中学习出来的!
卷积操作是如何进行的? - 像扫雷一样的过程
- 我们拿起一个 3x3 的垂直边缘探测器(卷积核)
- 将它覆盖在输入图片左上角的 3x3 区域上
- 将这个探测器矩阵,与它覆盖的图片区域的像素矩阵,进行对应位置相乘,然后全部相加的运算(数学上叫点积运算)
- 这个运算会得到一个单一的数字。这个数字,就代表了当前区域,与垂直边缘这个特征的匹配程度。如果这个区域恰好有一个强烈的垂直边缘,这个数字就会很大;如果这个区域很平滑,数字就会接近0。
- 然后,我们将这个探测器向右移动一个像素(步长 stride),重复上面的运算得到第二个数字。
- …就这样,这个探测器像玩扫雷一样,从左到右、从上到下地,滑过整张输入图片。
- 最终,它会生成一张新的、尺寸稍小的二维矩阵。这张新矩阵,就被称为
特征图(Feature Map)
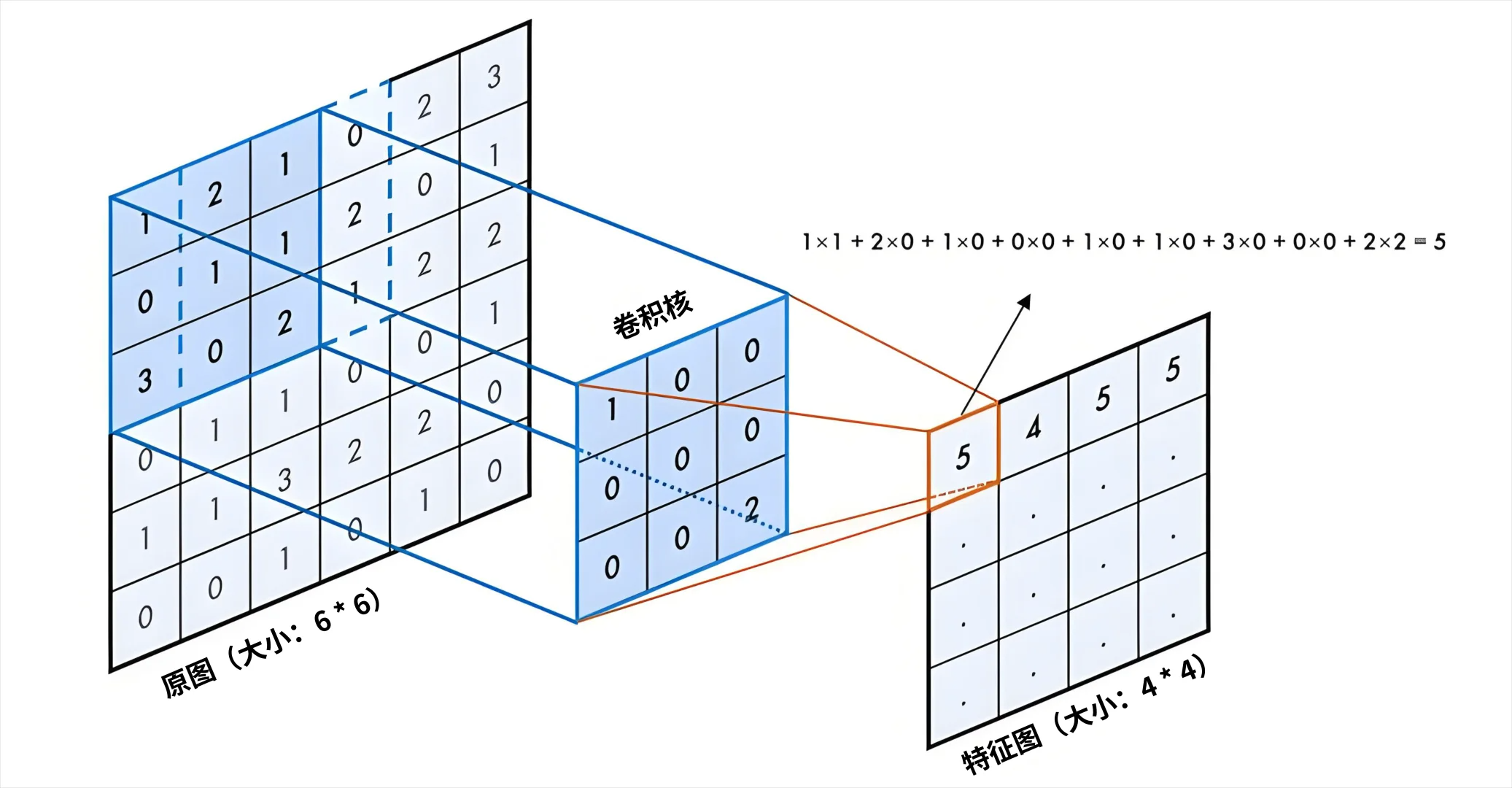
特征图是什么
- 它不再是原始的像素图。它是原始图片经过垂直边缘探测器过滤后的结果。在这张图上,数值越亮(大)的地方,就代表原始图片对应位置,存在一个越强烈的垂直边缘。
- 我们会有很多个不同的
卷积核!一个卷积层,可能会同时使用几十上百个不同的特征探测器(比如64个)
- 一个探测垂直边缘
- 一个探测水平边缘
- 一个探测角点
- 一个探测红色斑点
- ...
- 每一个卷积核,都会在原始图片上扫一遍,生成一张属于它自己的
特征图- 所以,一个拥有64个卷积核的卷积层,在接收一张输入图片后,会输出64张不同的特征图!这64张图,就构成了对原始图片在不同维度上的、丰富的特征描述。
CNN如何解决FCNN的两大灾难问题?
- 参数共享: 这是CNN最天才的设计!在扫雷的过程中,同一个特征探测器(卷积核),是被重复使用在图片的所有位置上的。这意味着,我们只需要学习这一个3x3 卷积核的9个权重,就能处理整张图片!相比FCNN每个连接都有独立权重,这极大地减少了参数数量,从亿级别骤降到了万级别,彻底解决了参数爆炸问题。
- 保留空间结构: 卷积操作,本身就是在二维空间上进行的。它完美地保留了像素之间的
邻里关系,并且它学到的特征(比如一个角点),本身就是由局部空间关系构成的。这使得CNN在处理图像时,能够保留物体的局部特征,而不是将所有信息都压缩到一个全局向量中。
4.激活函数层-引入非线性
激活函数层(Activation Layer)
- 职责: 在卷积层输出的特征图上,应用一个非线性的激活函数(最常用的是
ReLU--Rectified Linear Unit)。- ReLU做了什么: 极其简单!ReLU(x)=max(0,x)。也就是说,它会遍历特征图上的每一个数值,将所有小于0的数值,全部变成0,大于0的数值保持不变。
- 为什么需要非线性:
- 如果没有激活函数,或者激活函数是线性的,那么无论你的神经网络有多少层,它本质上都只是一个简单的线性模型的叠加,其表达能力非常有限,无法学习复杂的数据模式。
- 引入ReLU这样的非线性开关,就赋予了神经网络掰弯的能力。它
能够拟合极其复杂的、非线性的决策边界,从而极大提升了模型的表达能力。这就像只用直线无论如何也画不出一个圆,但一旦你有了曲线这个工具,就能创造无限可能。
5.池化层-信息降维与精华提炼
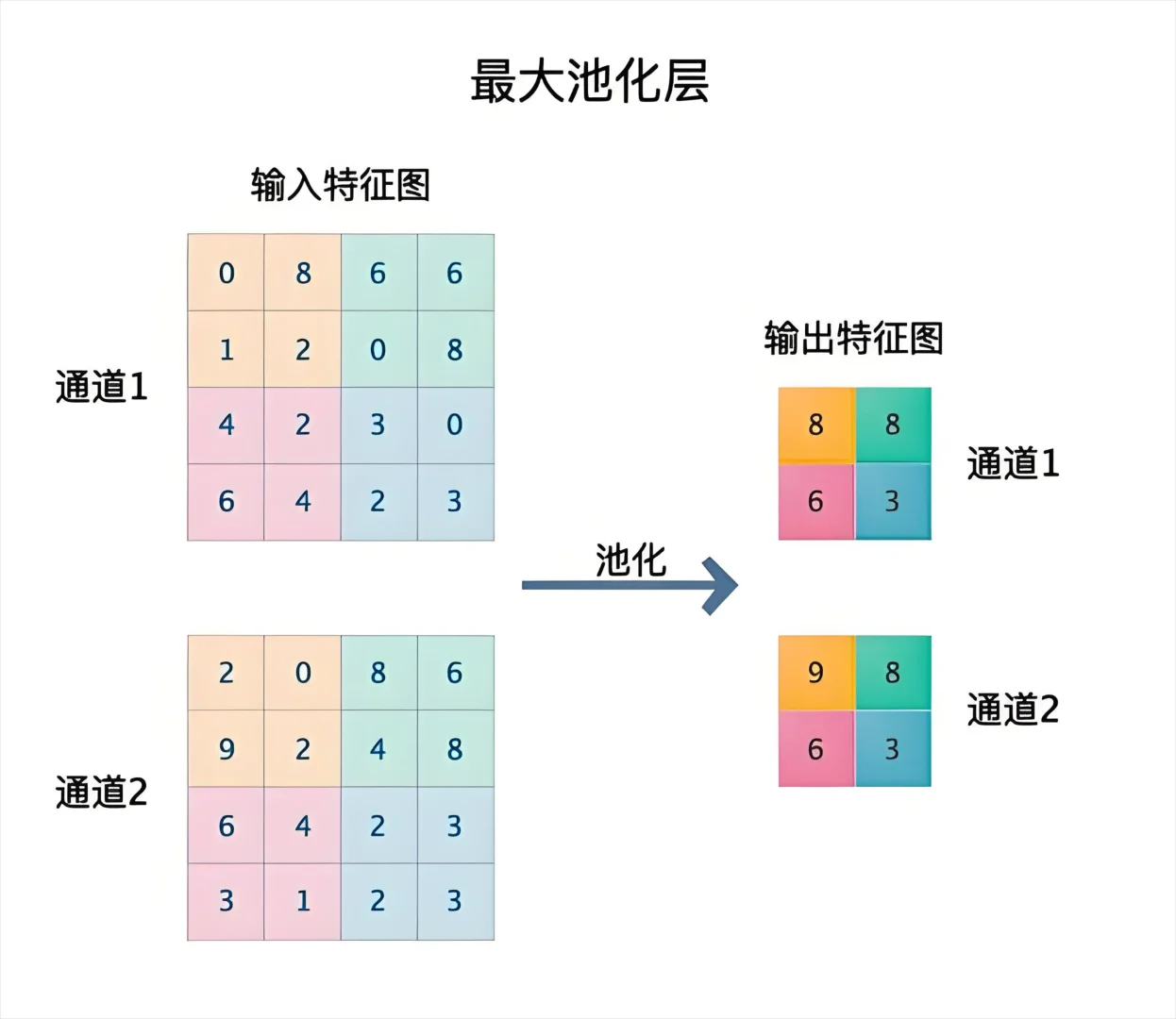
池化层(Pooling Layer)
- 职责: 对经过激活的特征图,进行
下采样(Down-sampling),即降低其尺寸。- 最常用的操作:
最大池化(Max Pooling)
- a.我们定义一个
池化窗口,比如2x2- b.将这个窗口,不重叠地滑过整张特征图。
- c:在每个 2x2 的窗口内,只保留其中最大的那个数值,扔掉其他3个,
- d.最终,一张 24x24 的特征图,经过2x2的最大池化后,就会变成一张12x12 的新特征图。
- 池化层带来了的好处:
- 进一步减少参数和计算量:特征图的尺寸变小了,后续层需要处理的数据量也相应减少,提升计算效率。
- 提供平移不变性(Translation Invariance):这是池化层最核心的价值!想象一下,在一个 2x2 的区域内,无论那个最强的边缘特征,出现在左上角、右上角、还是其他位置,只要它在这个区域内,经过最大池化后,输出的结果都是一样的!这意味着,模型对特征的微小位移,变得不那么敏感了。一只猫的眼睛,无论是在图片的(100,100)像素位置,还是在(102,101)像素位置,对于后续的网络来说,感知到的信息是相似的。这极大地提升了模型的泛化能力。
- 增大感受野:经过池化后,新特征图上的一个像素点,实际上融合了原始特征图上一片区域的信息。这使得更深层的网络,能够看到更宏观的特征。
6.全连接层-最终投票
个完整的CNN,就是将上面这"卷积一激活一池化"的三连招,像搭乐高一样重复堆叠多次,然后再在网络的末端,接上几层我们熟悉的全连接层,来进行最终的分类或识别。
这个层层递进的过程,完美地模拟了我们大脑的层次化特征提取
- 浅层网络: 卷积核学习到的是边缘、颜色、纹理等低级特征。
- 中层网络: 将低级特征组合,学习到眼睛、鼻子、耳朵等中级特征
- 深层网络: 将中级特征组合,学习到猫脸、狗脸等高级、抽象的概念特征
- 最后的全连接层: 像一个最终裁判,它看着前面所有层提取出的各种高级特征然后做出最终的投票:根据我看到的“猫脸“特征、'猫耳朵"特征、"猫尾巴”特征,我判断这张图是'猫'的概率是98%。
7.CNN里程碑架构
在CNN的发展史上,出现过几个里程碑式的、不断加深的网络架构:
- LeNet-5(1998):Yann LeCun提出的开山鼻祖,用于手写数字识别,只有5层,奠定了卷积+池化+全连接的经典范式。
- AlexNet(2012):引爆了深度学习革命的火炬手。它通过使用更深的网络(8层)、更大的数据集(ImageNet)、ReLU激活函数和Dropout技术,在当年的ImageNet图像识别大赛中,以碾压性的优势夺冠,震惊了整个学术界和工业界,VGGNet(2014):探索了用更小的卷积核(3x3)和更深的网络(16-19层)来提升性能的可能性。
- GoogLeNet(2014):引入了Inception模块,在一个网络层中,同时使用不同尺寸的卷积核,来捕捉不同尺度的特征,并提升了计算效率。
- ResNet(Residual Network,2015):这是CNN发展史上又一个重要的突破!它通过引入
残差连接(Residual Connection)或快捷连接(ShortcutConnection),巧妙地解决了网络越深,越难训练的问题。它允许信息跳层传播,使得训练上百层、甚至上千层的超深神经网络成为了可能,极大地提升了模型的性能和精度。
8.未来展望
CNN的出现,是AI发展史上的一座丰碑。它不仅定了现代计算机视觉的基石其局部连接、参数共享、层次化特征的思想,也深刻地影响了后续的AI架构设计。当然,技术总是在不断演进。
- CNN的挑战:CNN在捕捉图像的全局、长距离依赖关系方面,能力相对较弱(因为卷积核是局部的)
- Vision Transformer(ViT)的崛起:近年来,我们在注意力机制那篇里详述的Transformer架构,开始跨界进入视觉领域。ViT通过将一张图片切成一个个小块,然后将这些小块视为语言中的单词,再利用自注意力机制来计算任意两个小块之间的关联性。这使得它在捕捉全局上下文信息方面,呈现出比CNN更强的能力,并在许多视觉任务上,取得了超越CNN的性能。
未来的视觉模型,很可能不再是CNN或Transformer的二选一,而是两者的结合。比如,用CNN强大的局部特征提取能力,作为网络的前几层;然后,再用Transformer强大的全局关系建模能力,作为网络的高层,实现优势互补。
9.总结
- 核心使命:解决传统全连接神经网络在处理图像时,面临的
参数爆炸和空间结构丢失两大灾难, - 灵感来源:模仿生物视觉系统的
局部感受和层次化特征提取机制。 - 三大核心法宝:
- 卷积层(Convolution):利用参数共享的
卷积核(滤波器),高效地从图像中提取局部特征(如边缘、纹理) - 激活函数(Activation):引入非线性(如
ReLU),极大地提升网络的表达能力。 - 池化层(Pooling):进行下采样,减少计算量,并提供平移不变性,提升模型泛化能力。
- 卷积层(Convolution):利用参数共享的
- 工作模式:通过堆叠"卷积一激活一池化"的组合,实现从低级特征(点线)到高级特征(物体概念)的层次化抽象。
- 未来发展:虽然面临着Vision Transformer(ViT)的挑战,但CNN的核心思想依然是基石,未来将走向与Transformer的深度融合,实现更强大的视觉模型。